Chartered Institute
of Linguists
The best way to learn a language

What is the most efficient way to learn a language? Petar Milin and Dagmar Divjak are turning to an algorithm to find out
Learning a new language is an incredibly daunting task for adults. While newspaper headlines may give the impression that the interest in language learning is on the wane, fluency in a foreign language is something many aspire to. Over the past decade, language learning apps have gained immensely in popularity, with the industry leader alone attracting nearly 10 million active users daily.
Taking their cues from the gaming industry, these apps offer a high level of user engagement and retention but fall short when it comes to helping users achieve mastery. What is it that makes learning a foreign language so challenging? At the University of Birmingham, we use artificial intelligence to understand how languages can be taught more efficiently.
Grounded in two disciplines – linguistics and psychology – we rely on mathematical algorithms modelled on research into learning to develop a new account of what needs to be learnt. The aim is to offer an effective, sustainable and rewarding experience for language learners, whatever the medium of instruction.
The building blocks for learning
One well-known principle of learning is error-correction learning. This assumes that an organism gradually builds relevant relationships between elements in its environment to gain a better understanding of the world. Learning a language also involves building relations, correcting errors and gradually improving our performance.
But what do we need to pick up when we are exposed to a new language? Natural languages exhibit a unique property: a small number of words are very frequent, but the vast majority are rarely used. In English, for example, 10 words make up 25% of usage1 and you need only around 1,000 words to be able to understand 85% of what an average speaker says. This observation has been used to make informed decisions about learning priorities, in particular which words should be taught first.
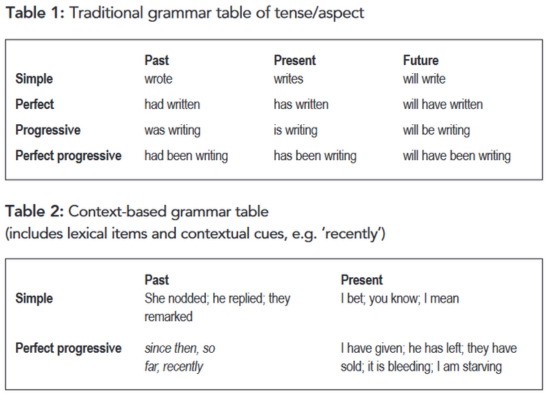
To illustrate our approach, let’s look at an area that is notoriously difficult for language learners: tense/aspect. Generally, English grammars assume the existence of 12 tense/aspect combinations. These arise from three tenses and four aspects (see Table 1). In a traditional grammatical approach, you would define the abstract meaning of each tense and each aspect separately. Tense is relatively easy: if something happened yesterday, you use a past tense; if something will happen tomorrow, you use a future tense. Aspect can also be explained concisely: the simple aspect is there to express a fact; the perfect is for actions which are completed but retain some relevance to the present situation; the progressive describes an event that happens over a period of time. It’s an economical method and works to teach forms and their labels, but it is terribly inadequate when it comes to enabling learners to use those forms.
An approach that factors in actual usage yields much more effective results. If we retain the relation between verbs and tense/aspect markers we see that the cells (Table 1) are occupied by a different subset of verbs (see Table 2): some verbs occur preferably with specific tense/ aspect markers (‘replied’ in the simple past), while other tense/aspect combinations are typically accompanied by contextual elements (‘since then’ and the past perfect).
While this provides learners with knowledge they can apply directly, it does look like madness: do we really memorise these tense and aspect preferences for each individual verb? When we use computational techniques to check millions of examples it quickly becomes clear that those 12 cells (Table 1) aren’t all equally important: the present and past simple make up more than 80% of all examples. This suggests that users do not get exposed to all forms equally, and this has implications for learning.
Building an algorithm
To explore how this system would be learnt we turned a simple but fundamental rule of error-correction learning – the Rescorla-Wagner rule2 – into a computational algorithm. In this way we have a model that mimics how people learn from raw language data in a naturalistic way. The algorithm uses the target form’s immediate context as cue(s) to inform the choice of verb form, as people do. For example, in the sentence ‘Almost a year later nothing has happened’, the cues are individual words (what we refer to as ‘1-grams’), including ‘almost’, ‘year’, ‘later’, ‘nothing’, ‘a’, but also ‘2-grams’, such as ‘almost#a’, ‘a#year’, and ‘3-grams’, e.g. ‘a#year#later’ alongside the verb ‘happen’.
After the model has worked its way through a large number of examples, calculating the strength of co-occurrence between the 1-, 2- and 3-grams and forms of the verb ‘happen’, the model is tested. It is given a sentence where the word ‘happen’ is missing and asked to fill the gap with a suitable form of the verb. Overall, our model learns to use tense and aspect forms rather well, makes choices that feel natural to English language users and is able to suggest possible alternatives. (Often more than one form is possible; in the example sentence, ‘has happened’, ‘had happened’ or ‘is happening’ could all be used equally well.)
We can also look under the hood of this algorithm and identify the cues that support learning.3 This is where frequency of use comes in again: the verb system appears to consist of two types of tense/aspect combination.
Simple tenses, such as simple present and simple past, are very frequently used and therefore strongly associated with specific lexical elements, i.e. regular verbs.
Learners need to be exposed to these verbs in their preferred tense/aspect forms, for instance ‘you know’, ‘I mean’, ‘he replied’, ‘she nodded’. But there are also more complex tense/aspect combinations which are rarely used and are therefore cued by contextual elements (1-, 2-, 3- and 4-grams, e.g. ‘recently’ and ‘since then’). To become a proficient user of these more complex verb forms, the learner needs to be exposed to context that supports the use of these forms.
Practically, when teaching the English tense/aspect system, learners would work their way through the tense/aspect combinations in order of frequency of occurrence, starting with the simple past and present, and focusing on the verbs that occur in these tenses. When this knowledge is secure, attention could gradually shift to the complex tenses, and the contextual elements that support their use.
Comparisons with already established tenses can be drawn where appropriate, e.g simple vs progressive past. Crucially, the fine semantic differences between the different ways of expressing, e.g, the past would come from a discussion of the differences between the contextual elements that support each of the relevant tense/aspect combinations. This would replace the current reliance on abstract concepts, such as present relevance, that are typically used to explain the meaning, and hence use, of tense/aspect combinations.
In other words, if we follow the science, and learn from data the way first-language users learn from data, and do this using copious amounts of data, we find relevant patterns that are difficult to spot with the naked eye. These patterns are highly relevant for understanding how the system works and hence how it should be taught. Our approach relies on these structures that are detected by applying basic principles of learning without reliance on linguistic rules.
An additional strength of our approach is that we can let the algorithm learn from data that matches specific learning goals in terms of genre, style, topic, etc. For example, the conventions for tense/aspect use differ between, say, academic articles and creative fiction. Training our algorithm on examples from the genre or style you are trying to learn or teach will generate tailor- made recommendations.
An approach to language founded on principles of learning also enables teachers to shift the focus away from prescribing usage through rules, towards describing usage in a way that directs learners’ attention to the type of cues that are useful for learning a particular structure. After all, there is an infinite number of things we might want to say and we cannot teach solutions to an infinite number of problems, but we can teach our students where to look to learn to solve any problem.
By equipping learners with a long-term learning strategy, we support them in building a bank of knowledge that is tailored to the task at hand. This increases their chances of developing efficient memory traces that resemble those of native language users and offers a more effective, sustainable and rewarding language-learning experience.
Figure 1: The prevalence of each tense/aspect in the British National Corpus
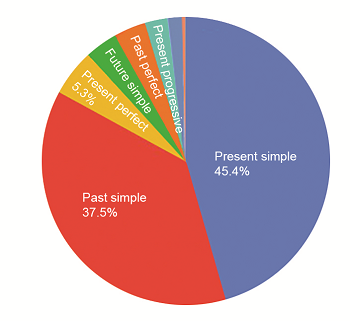
Figure 2: Prevalence of cues that enable language users to determine which aspect/tense to use. 1-grams are one-word contextual cues (eg 'almost'), 2-grams are two-word contextual cues (eg 'a#year'), lexical items refer to the verbs that are used (eg 'reply').

www.youtube.com/@outofourminds8219; X @ooominds; outofourminds.bham.ac.uk. For teaching resources see outofourminds.bham.ac.uk/resources.
Notes
1 ‘The’, ‘be’, ‘to’, ‘of’, ‘and’, ‘a’, ‘in’, ‘that’, ‘have’, ‘I’.
2 Rescorla, RA and Wagner, RA (1972) ‘A Theory of Pavlovian Conditioning: Variations in the effectiveness of reinforcement and non-reinforcement’. In Black, H and Proksay, WF, Classical Conditioning II, Appleton-Century-Crofts, 64-99
3 Romain, L and Divjak, D (2024) ‘The Types of Cues That Help You Learn: Pedagogical implications of a computational simulation on learning the English tense/aspect system from exposure’. In Pedagogical Linguistics, John Benjamins; www.jbe-platform.com/content/journals/10.1075/pl.23003.rom
Petar Milin is a professor of Psychology of Language and Language Learning at the University of Birmingham, where he also leads the Out of Our Minds research team. His research primarily focuses on the pivotal role of learning for human language, its behaviour and use. His methodological approach integrates experimental research with computational modelling and advanced statistical data analysis.
Dagmar Divjak is a Professor of Linguistics at the University of Birmingham where her interdisciplinary research group uses computational algorithms that mimic how humans learn to develop new ways of describing language and transform how we teach foreign languages.
This article is reproduced from the Summer 2024 issue of The Linguist. Download the full edition here.







